Hello,
After reading your paper ("Wang, Xiao, Hanna Krasowski, and Matthias Althoff. “CommonRoad-RL: a configurable reinforcement learning environment for motion planning of autonomous vehicles.” ") ; I tried point-goal navigation on the simplest dataset available: “DEU_Hhr-1_1.xml”; no dynamic obstacle.
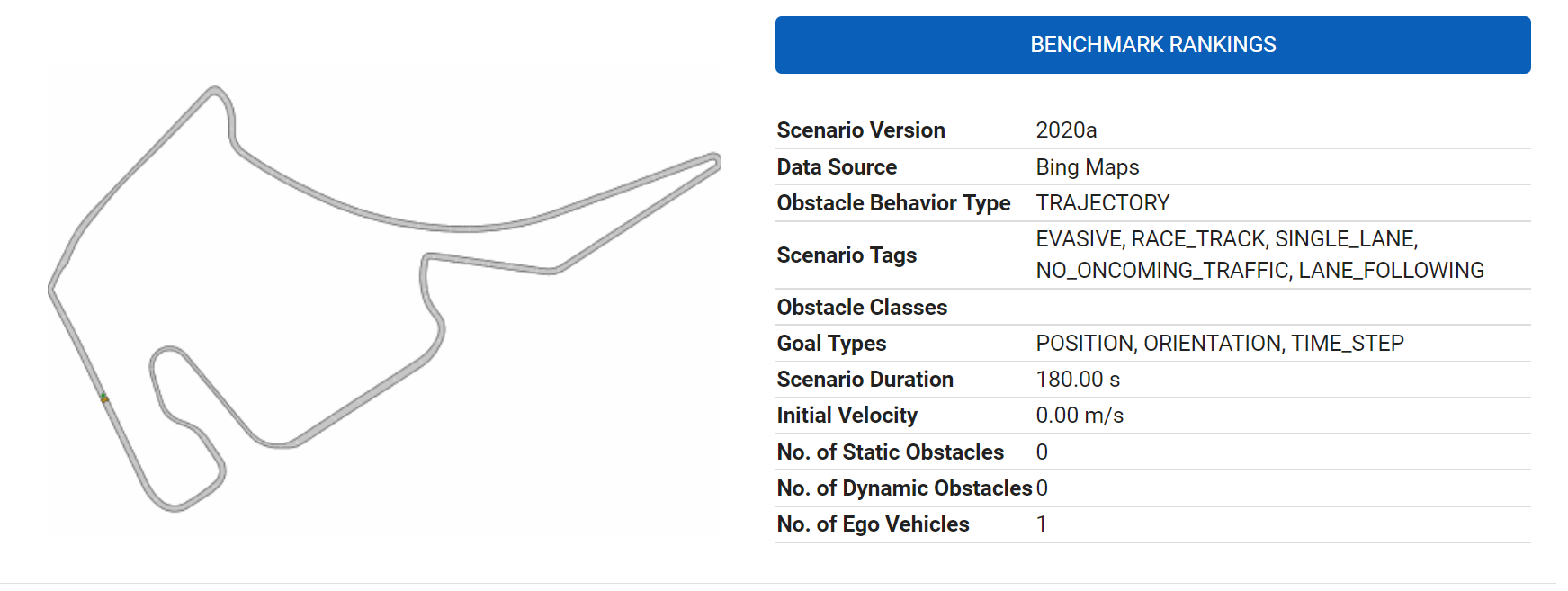
With this environment configuration (chosen from the learning curves result and the env’s HPs given in the bottom of the paper).
action_configs:
action_base: acceleration
action_type: discrete
continuous_collision_checking: true
lat_steps: 3
long_steps: 3
planning_horizon: 1.0
cache_navigators: false
ego_configs:
observe_a_ego: true
observe_global_turn_rate: true
observe_is_friction_violation: true
observe_relative_heading: true
observe_remaining_steps: true
observe_steering_angle: false
observe_v_ego: true
flatten_observation: true
goal_configs:
observe_distance_goal_lat: true
observe_distance_goal_long: true
observe_distance_goal_long_lane: false
observe_distance_goal_orientation: true
observe_distance_goal_time: true
observe_distance_goal_velocity: true
observe_euclidean_distance: false
observe_is_goal_reached: true
observe_is_time_out: true
relax_is_goal_reached: false
lanelet_configs:
distances_and_ids_multilanelet_waypoints:
- - -1000
- 0
- 1000
- - 0
- 1
distances_route_reference_path:
- -1000
- 0
- 5
- 15
- 100
dynamic_extrapolation_samples:
- 0.1
- 0.25
- 1
- 2
non_strict_check_circle_radius: 0.5
observe_distance_togoal_via_referencepath: false
observe_dynamic_extrapolated_positions: false
observe_is_off_road: true
observe_lane_curvature: false
observe_lat_offset: true
observe_left_marker_distance: true
observe_left_road_edge_distance: true
observe_right_marker_distance: true
observe_right_road_edge_distance: true
observe_route_multilanelet_waypoints: false
observe_route_reference_path: false
observe_static_extrapolated_positions: false
static_extrapolation_samples:
- 1
- 2
- 5
- 10
- 25
strict_off_road_check: true
max_lane_merge_range: 5000.0
render_configs:
render_ccosy_nav_observations: false
render_combine_frames: false
render_dynamic_extrapolated_positions: false
render_ego_lanelet_center_vertices: false
render_follow_ego: true
render_global_ccosy: false
render_lidar_circle_surrounding_beams: false
render_lidar_circle_surrounding_obstacles: false
render_local_ccosy: false
render_range:
- 100.0
- 15.0
render_road_boundaries: false
render_skip_timesteps: 1
render_static_extrapolated_positions: false
render_surrounding_area: false
render_surrounding_obstacles_lane_based: false
reward_configs_dense:
reward_goal_distance_coefficient: 0.2
reward_obs_distance_coefficient: 0.1
reward_configs_hybrid:
reward_close_goal_orientation: 1.0
reward_close_goal_velocity: 1.0
reward_closer_to_goal_lat: 5.0
reward_closer_to_goal_long: 5.0
reward_collision: -1000.0
reward_friction: 0.0
reward_friction_violation: 0.0
reward_get_close_goal_time: 1.0
reward_goal_reached: 2000.0
reward_jerk_lat: 0.0
reward_jerk_long: 0.0
reward_lat_distance_reference_path: 0.0
reward_lateral_velocity: 0.0
reward_long_distance_reference_path: 0.0
reward_off_road: -1000.0
reward_reverse_driving: 0.0
reward_safe_distance_coef: -1.0
reward_stay_in_road_center: 0.0
reward_stop_sign_acc: 0.0
reward_stop_sign_vel: 0.0
reward_time_out: -100.0
stop_sign_vel_zero: 0.0
reward_configs_sparse:
reward_collision: -50.0
reward_friction_violation: 0.0
reward_goal_reached: 50.0
reward_off_road: -20.0
reward_time_out: -10.0
reward_type: sparse_reward
surrounding_configs:
fast_distance_calculation: true
lane_circ_sensor_range_radius: 100.0
lane_rect_sensor_range_length: 100.0
lane_rect_sensor_range_width: 7.0
lidar_circle_num_beams: 20
lidar_sensor_radius: 50.0
observe_is_collision: true
observe_lane_change: true
observe_lane_circ_surrounding: true
observe_lane_rect_surrounding: false
observe_lidar_circle_surrounding: false
observe_relative_priority: false
observe_vehicle_lights: false
observe_vehicle_type: false
termination_configs:
terminate_on_collision: true
terminate_on_friction_violation: false
terminate_on_goal_reached: true
terminate_on_off_road: true
terminate_on_time_out: true
traffic_sign_configs:
observe_priority_sign: false
observe_right_of_way_sign: false
observe_stop_sign: false
observe_yield_sign: false
vehicle_params:
vehicle_model: 0
vehicle_type: 2
I kept the set of PPO2’s HPs (taken from the GIT).
cliprange: 0.2
ent_coef: 0.0
gamma: 0.99
lam: 0.95
learning_rate: 0.0005
n_steps: 1024
nminibatches: 1
noptepochs: 10
normalize: true
policy: MlpPolicy
I trained for ~ 500 000 steps but none of the learning episodes reached the goal.
r,l,t,is_collision,is_time_out,is_off_road,is_friction_violation,is_goal_reached
-10.0,28,3.422995,0,1,0,0,0
-10.0,12,5.45392,0,1,0,0,0
-10.0,38,7.572927,0,1,0,0,0
-10.0,21,9.595262,0,1,0,0,0
-10.0,11,11.603107,0,1,0,0,0
.
.
.
-10.0,1800,2017.406056,0,1,0,0,0
-10.0,1800,2028.488759,0,1,0,0,0
-10.0,1800,2039.525629,0,1,0,0,0
-10.0,1800,2050.564893,0,1,0,0,0
Every episodes finished with is_time_out = True whereas at beginning lenght << 1800 ; the dataset fixed the time limit to 1800 steps.
The paper shows worst performances with the hybrid reward; I will try.
Any idea for the settings ? Thanks in advance.
