Hello , I have been trying to generate a solution using the provided subset of the HighD dataset in tutorials and the configurations and hyperparameters in your paper but I can’t get the performance any better than the provided images below , I have trained the agent for 4* 200000 steps using continual learning but the performance is not getting any better , could this be due to the small data ? do I have to use the full highD dataset ?
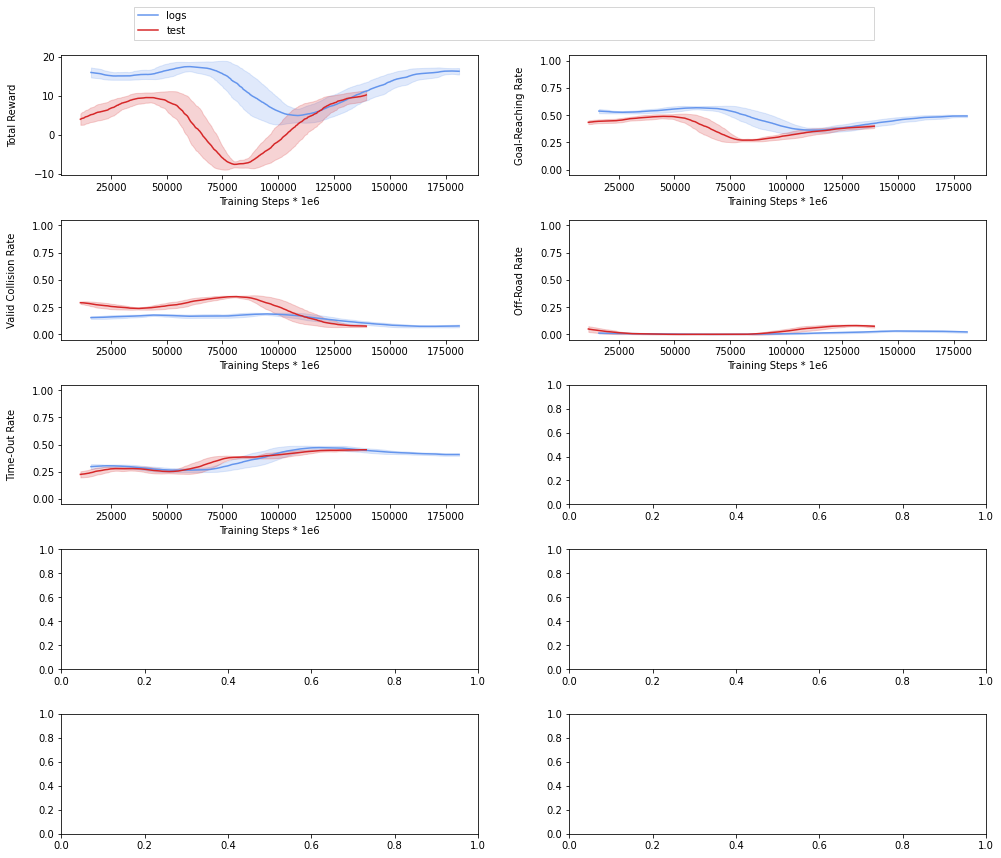

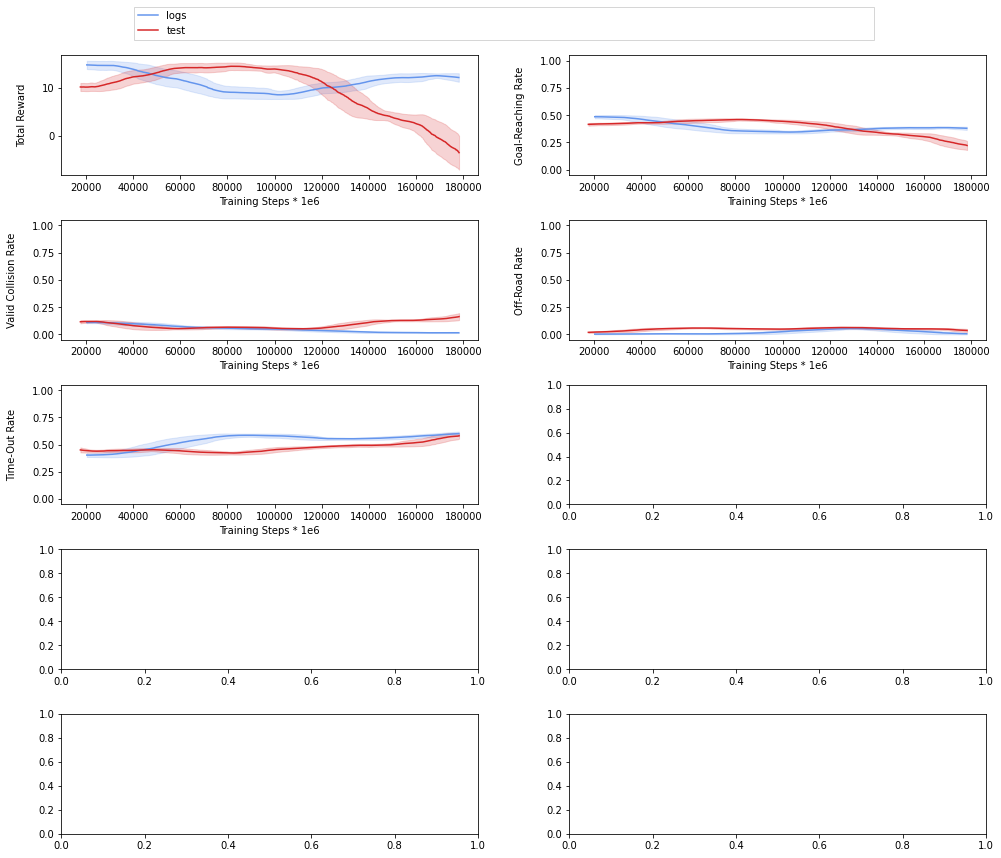
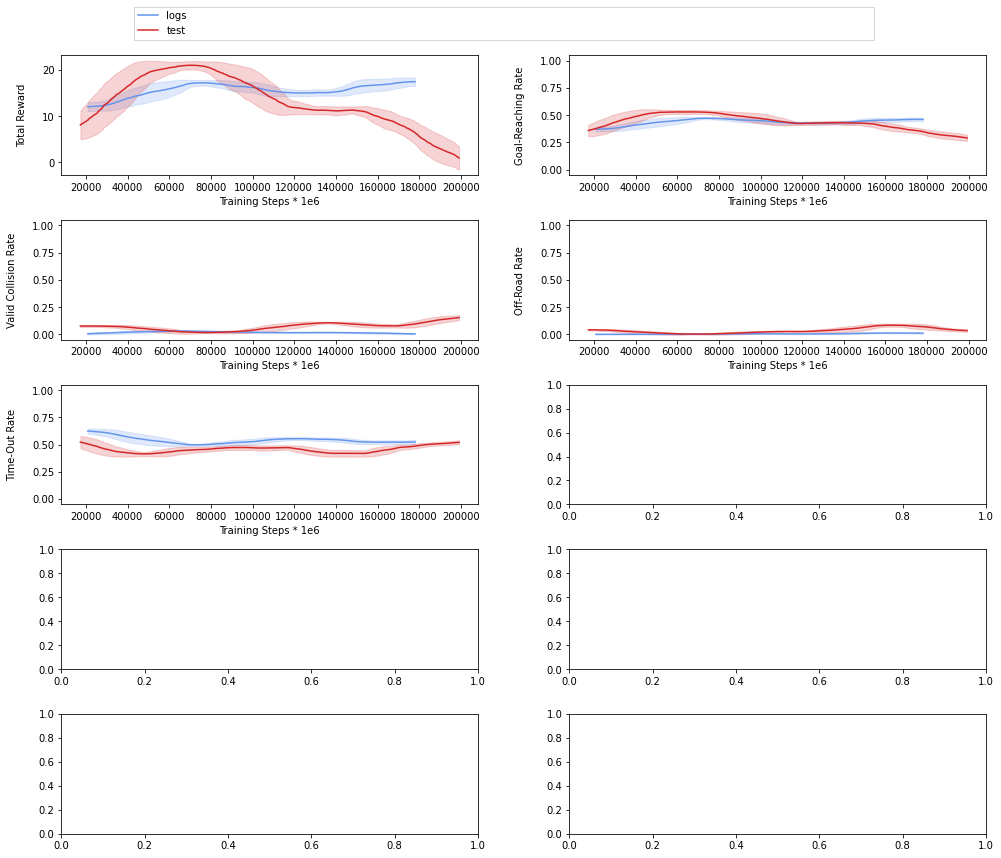
Hi Marihan,
could you please try to overfit with just one scenario? That should help us determine whether it’s really not overfitting or the size of the dataset isn’t right.
Best,
Philipp
1 Like
thank you very much for your reply , I have used a larger subset of the highD dataset (third of the dataset ) and got much better performance with the same configs and hyper-parameters , unfortunately I can’t use the entire dataset, I can use half the dataset at most due to hardware limitations so I want to make sure that the subset of data I am using is representative of the entire highD dataset but I don’t know how to ensure that, I would really appreciate any ideas suggested for that .
Hi marihan,
if you use hallf the dataset, simply choosing scenarios at random should be representative.
Best,
Philipp
1 Like