Hi Everyone,
=> I try to optimize the model for CommonRoad-RL, and I have some problems and questions about it.
Could you share any set of hyper parameters that gives good model result if do you have?
I am using MacOS, does this operating system cause any problem when running tutorials like incorrect outputs of cells?
Do I have to use Linux?
(I run all the Tutorials of CommonRoad-RL on MacOS and got output of them.)
=> Also, I run the Tutorial 5 is for finding the best hyper-parameters to optimization processes of Tutorial 2 and Tutorial 3. Then I put the best of the found by Tutorial 5 parameters to the file
commonroad-rl/commonroad_rl/hyperparams/ppo2.yml for the model training in Tutorial 2&3, the model never reached the good results during 100.000 #time steps with the hyper-parameters below.
{‘batch_size’: 64,
‘clip_range’: 0.2,
‘ent_coef’: 1e-07,
‘gae_lambda’: 0.999,
‘gamma’: 0.995,
‘learning_rate’: 0.0003,
‘n_epochs’: 10,
‘n_steps’: 512,
‘policy’: ‘MlpPolicy’}
=> Small part of the output of Tutorial 2 (Nearly same as last cell of the tutorial 3);
Eval num_timesteps=1000, episode_reward=-2.98 +/- 0.14
Episode length: 24.00 +/- 2.16
New best mean reward!
Saved vectorized and normalized environment to tutorials/logs/vecnormalize.pkl
Eval num_timesteps=2000, episode_reward=-1.54 +/- 0.34
Episode length: 13.33 +/- 1.89
New best mean reward!
Saved vectorized and normalized environment to tutorials/logs/vecnormalize.pkl
Eval num_timesteps=3000, episode_reward=-1.87 +/- 0.37
Episode length: 17.67 +/- 2.62
Eval num_timesteps=4000, episode_reward=-1.39 +/- 0.37
Episode length: 14.33 +/- 6.85
New best mean reward!
Saved vectorized and normalized environment to tutorials/logs/vecnormalize.pkl
Eval num_timesteps=5000, episode_reward=-1.46 +/- 0.14
Episode length: 13.67 +/- 3.86
Eval num_timesteps=6000, episode_reward=-1.63 +/- 0.30
Episode length: 15.67 +/- 3.30
Eval num_timesteps=7000, episode_reward=-1.24 +/- 0.06
Episode length: 11.67 +/- 0.47
New best mean reward!
*
*
*
Eval num_timesteps=23000, episode_reward=-1.21 +/- 0.21
Episode length: 12.00 +/- 3.56
Eval num_timesteps=24000, episode_reward=-1.24 +/- 0.25
Episode length: 12.00 +/- 2.16
Eval num_timesteps=25000, episode_reward=-1.07 +/- 0.12
Episode length: 9.00 +/- 0.00
New best mean reward!
Saved vectorized and normalized environment to tutorials/logs/vecnormalize.pkl
Eval num_timesteps=26000, episode_reward=-1.33 +/- 0.13
Episode length: 12.67 +/- 1.89
Eval num_timesteps=27000, episode_reward=-1.09 +/- 0.10
Episode length: 8.33 +/- 0.47
Eval num_timesteps=28000, episode_reward=-1.13 +/- 0.19
Episode length: 11.33 +/- 2.62
Eval num_timesteps=29000, episode_reward=-1.00 +/- 0.14
Episode length: 9.33 +/- 0.47
New best mean reward!
Saved vectorized and normalized environment to tutorials/logs/vecnormalize.pkl
Eval num_timesteps=30000, episode_reward=-1.59 +/- 0.41
Episode length: 12.00 +/- 3.56
Eval num_timesteps=31000, episode_reward=-0.95 +/- 0.08
Episode length: 9.33 +/- 0.47
New best mean reward!
=> If we look the output data, the reward always negative and it gives always “1” values for the “is_off_road” data.
You can see below image. Whatever I did, I never got the positive reward.
What is the defining of the reward function?
Is the negative reward meaning that the ego vehicle goes to off road?
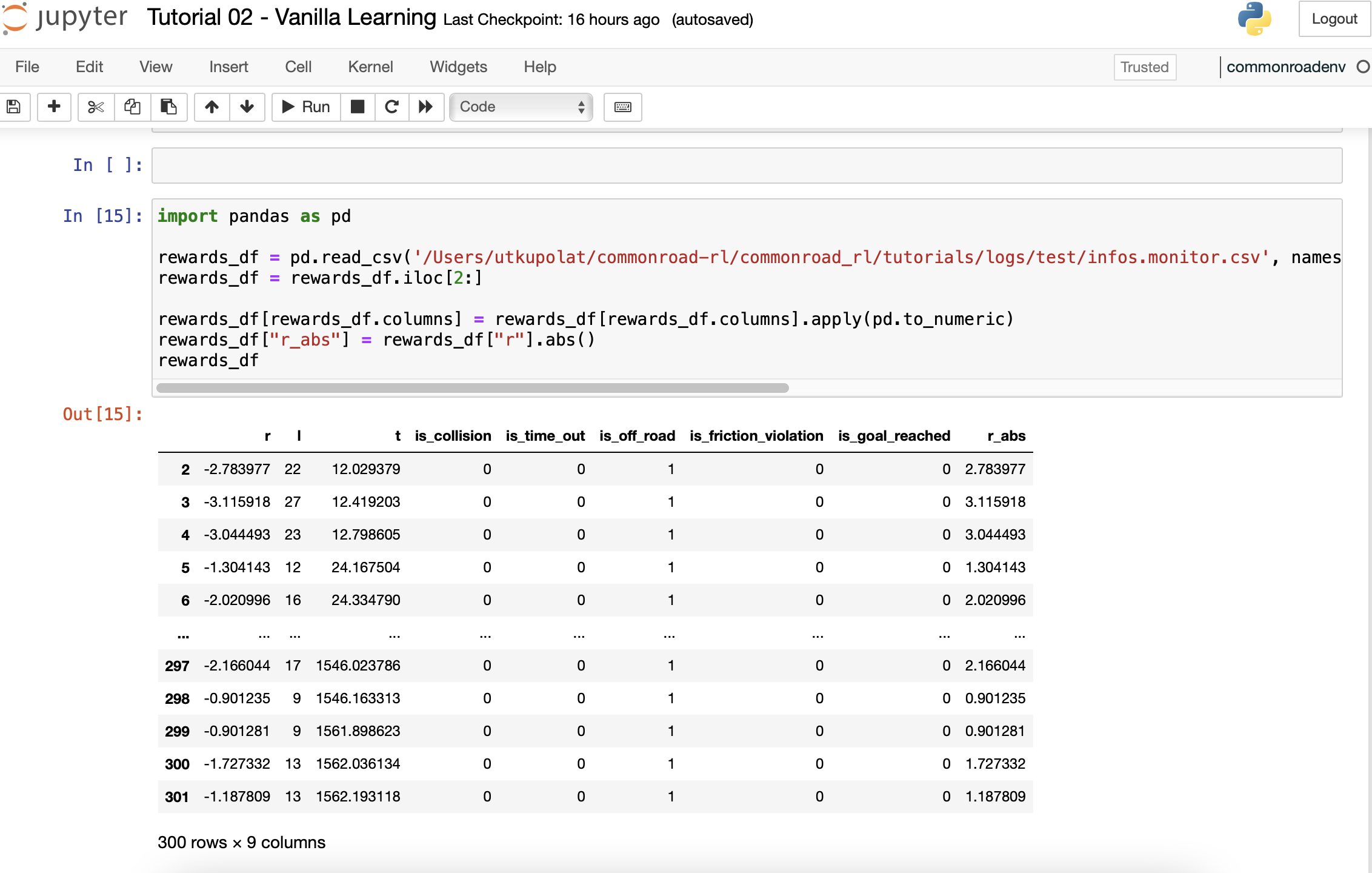
When I took the absolute values of the reward training curve looks like below images.


=> Then, all the files which are necessary for Tutorial 4 are created below after tutorials 2&3;
- a processed data directory at
tutorials/data/highD/pickles - a trained model at
tutorials/logs/best_model.zip - a saved environment wrapper
tutorials/logs/vecnormalize.pkl - a monitored information file
tutorials/logs/infos.monitor.csv - a recorded evaluation file
tutorials/logs/evaluations.npz
=> After that, I run the Tutorial 4. For the first cell of the Tutorial 4, I got the output below.
What is the meaning of this output? (I usually got the same output)
/Users/utkupolat/miniconda3/envs/commonroadenv/lib/python3.7/site-packages/stable_baselines/init.py:33: UserWarning: stable-baselines is in maintenance mode, please use Stable-Baselines3 (SB3) for an up-to-date version. You can find a migration guide in SB3 documentation.
“stable-baselines is in maintenance mode, please use Stable-Baselines3 (SB3) for an up-to-date version. You can find a migration guide in SB3 documentation.”
-0.0049770000000000005
-0.004924
-0.0049770000000000005
-0.004924
Saved logs.pdf to commonroad_rl/tutorials/logs
=> After the second cell of the Tutorial 4 (Render the Best Model), images of the scenarios created, however, it only gave the “i_collision” frames and “is_off_road” frames, other folders like “goal_reached”, “time_out” and “other” are fully empty.
Does the reason of this situation is bad model or even if the model is bad, there should be images of other scenarios?
=> Then, I run other cell which is “Generate CommonRoad Solution”, the output is like below, and it never reach the goal position.
This is also reason of bad model training or about MacOS?
/Users/utkupolat/miniconda3/envs/commonroadenv/lib/python3.7/site-packages/stable_baselines/init.py:33: UserWarning: stable-baselines is in maintenance mode, please use Stable-Baselines3 (SB3) for an up-to-date version. You can find a migration guide in SB3 documentation.
“stable-baselines is in maintenance mode, please use Stable-Baselines3 (SB3) for an up-to-date version. You can find a migration guide in SB3 documentation.”
[DEBUG] commonroad_rl.gym_commonroad.commonroad_env - Initialization started
/Users/utkupolat/miniconda3/envs/commonroadenv/lib/python3.7/site-packages/commonroad/scenario/lanelet.py:1279: ShapelyDeprecationWarning: STRtree will be changed in 2.0.0 and will not be compatible with versions < 2.
self._strtee = STRtree(list(self._buffered_polygons.values()))
[INFO] commonroad_rl.gym_commonroad.commonroad_env - Testing on commonroad_rl/tutorials/data/highD/pickles/problem_test with 16 scenarios
/Users/utkupolat/miniconda3/envs/commonroadenv/lib/python3.7/site-packages/gym/spaces/box.py:74: UserWarning: WARN: Box bound precision lowered by casting to float32
“Box bound precision lowered by casting to {}”.format(self.dtype)
[DEBUG] commonroad_rl.gym_commonroad.commonroad_env - Meta scenario path: commonroad_rl/tutorials/data/highD/pickles/meta_scenario
[DEBUG] commonroad_rl.gym_commonroad.commonroad_env - Training data path: /Users/utkupolat/commonroad-rl/pickles/problem_train
[DEBUG] commonroad_rl.gym_commonroad.commonroad_env - Testing data path: commonroad_rl/tutorials/data/highD/pickles/problem_test
[DEBUG] commonroad_rl.gym_commonroad.commonroad_env - Initialization done
[DEBUG] commonroad_rl.gym_commonroad.commonroad_env - Number of scenarios left 16
/Users/utkupolat/commonroad-rl/commonroad_rl/gym_commonroad/utils/navigator.py:383: ShapelyDeprecationWarning: The ‘cascaded_union()’ function is deprecated. Use ‘unary_union()’ instead.
for geom in polygons_to_merge
Step: 1, Reward: [-0.18738179], Done: [False]
Step: 2, Reward: [-0.18450156], Done: [False]
Step: 3, Reward: [-0.18161601], Done: [False]
Step: 4, Reward: [-0.17872643], Done: [False]
Step: 5, Reward: [-0.17583042], Done: [False]
Step: 6, Reward: [-0.17292754], Done: [False]
Step: 7, Reward: [-0.17003055], Done: [False]
Step: 8, Reward: [-0.16715086], Done: [False]
Step: 9, Reward: [-0.16430138], Done: [False]
Step: 10, Reward: [-0.16150501], Done: [False]
Step: 11, Reward: [-0.15878226], Done: [False]
Step: 12, Reward: [-0.15616754], Done: [False]
Goal not reached
Termination reason: is_off_road
[DEBUG] commonroad_rl.gym_commonroad.commonroad_env - Number of scenarios left 15
Step: 0, Reward: [-0.15369895], Done: [ True]
Step: 1, Reward: [-0.1957575], Done: [False]
Step: 2, Reward: [-0.19479516], Done: [False]
Step: 3, Reward: [-0.19383146], Done: [False]
Step: 4, Reward: [-0.19286661], Done: [False]
Step: 5, Reward: [-0.19190899], Done: [False]
Step: 6, Reward: [-0.19094338], Done: [False]
Step: 7, Reward: [-0.18998677], Done: [False]
Step: 8, Reward: [-0.18903005], Done: [False]
Step: 9, Reward: [-0.188078], Done: [False]
Goal not reached
Termination reason: is_off_road
[DEBUG] commonroad_rl.gym_commonroad.commonroad_env - Number of scenarios left 14
/Users/utkupolat/miniconda3/envs/commonroadenv/lib/python3.7/site-packages/commonroad_route_planner/route.py:309: RuntimeWarning: invalid value encountered in true_divide
return (x_d * y_dd - x_dd * y_d) / ((x_d ** 2 + y_d ** 2) ** (3. / 2.))
Step: 0, Reward: [-0.1871388], Done: [ True]
Step: 1, Reward: [-0.17983317], Done: [False]
Step: 2, Reward: [-0.17500028], Done: [False]
Step: 3, Reward: [-0.17015113], Done: [False]
Step: 4, Reward: [-0.16529708], Done: [False]
Step: 5, Reward: [-0.16044208], Done: [False]
Step: 6, Reward: [-0.15559424], Done: [False]
Step: 7, Reward: [-0.15077502], Done: [False]
Step: 8, Reward: [-0.14600717], Done: [False]
Step: 9, Reward: [-0.14132138], Done: [False]
Step: 10, Reward: [-0.13676913], Done: [False]
Step: 11, Reward: [-0.132402], Done: [False]
Step: 12, Reward: [-0.12829745], Done: [False]
Goal not reached
Termination reason: is_off_road
[DEBUG] commonroad_rl.gym_commonroad.commonroad_env - Number of scenarios left 13
Step: 0, Reward: [-0.12452681], Done: [ True]
Step: 1, Reward: [-0.22710644], Done: [False]
Step: 2, Reward: [-0.22550842], Done: [False]
Step: 3, Reward: [-0.22390683], Done: [False]
Step: 4, Reward: [-0.22230022], Done: [False]
Step: 5, Reward: [-0.22069095], Done: [False]
Step: 6, Reward: [-0.2190909], Done: [False]
Step: 7, Reward: [-0.217498], Done: [False]
Step: 8, Reward: [-0.21592323], Done: [False]
Step: 9, Reward: [-0.21438073], Done: [False]
Goal not reached
Termination reason: is_off_road
*
*
*
[DEBUG] commonroad_rl.gym_commonroad.commonroad_env - Number of scenarios left 2
Step: 0, Reward: [-0.1673553], Done: [ True]
Step: 1, Reward: [-0.16994743], Done: [False]
Step: 2, Reward: [-0.16573276], Done: [False]
Step: 3, Reward: [-0.16150708], Done: [False]
Step: 4, Reward: [-0.15727931], Done: [False]
Step: 5, Reward: [-0.15304792], Done: [False]
Step: 6, Reward: [-0.148826], Done: [False]
Step: 7, Reward: [-0.14463142], Done: [False]
Step: 8, Reward: [-0.14048003], Done: [False]
Step: 9, Reward: [-0.13640518], Done: [False]
Step: 10, Reward: [-0.13243747], Done: [False]
Step: 11, Reward: [-0.12863213], Done: [False]
Step: 12, Reward: [-0.12505625], Done: [False]
Goal not reached
Termination reason: is_off_road
[DEBUG] commonroad_rl.gym_commonroad.commonroad_env - Number of scenarios left 1
Step: 0, Reward: [-0.12177388], Done: [ True]
Step: 1, Reward: [-0.18203515], Done: [False]
Step: 2, Reward: [-0.18131742], Done: [False]
Step: 3, Reward: [-0.18059686], Done: [False]
Step: 4, Reward: [-0.17987078], Done: [False]
Step: 5, Reward: [-0.17915034], Done: [False]
Step: 6, Reward: [-0.17842796], Done: [False]
Step: 7, Reward: [-0.17770156], Done: [False]
Step: 8, Reward: [-0.1769722], Done: [False]
Step: 9, Reward: [-0.17624134], Done: [False]
Goal not reached
Termination reason: is_off_road
[DEBUG] commonroad_rl.gym_commonroad.commonroad_env - Number of scenarios left 0
Step: 10, Reward: [-0.1755135], Done: [ True]
Thanks!